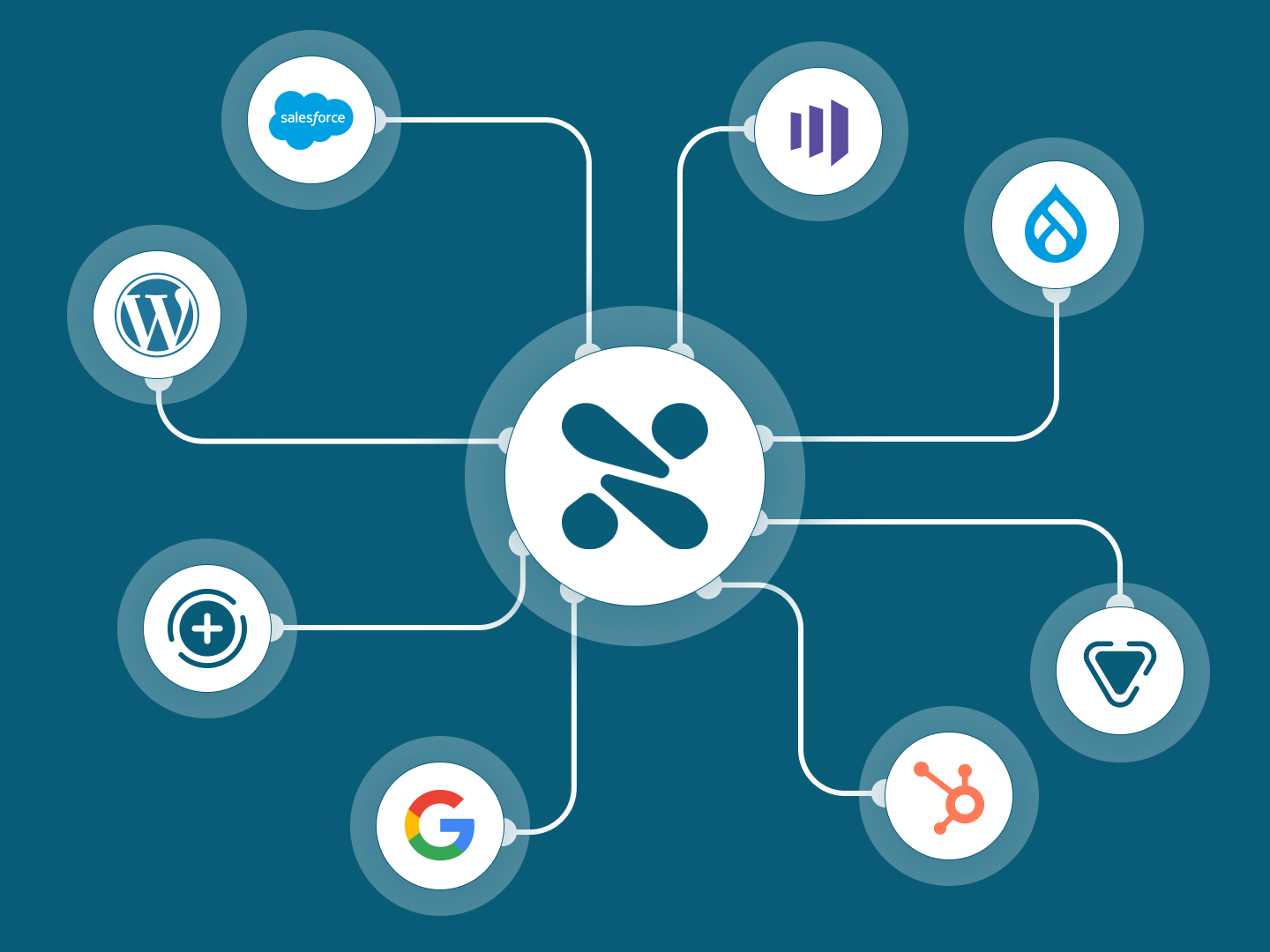




Control your entire digital experience
Integrate all your existing systems within a single flexible platform and easily orchestrate your content across all your web properties.
Learn more
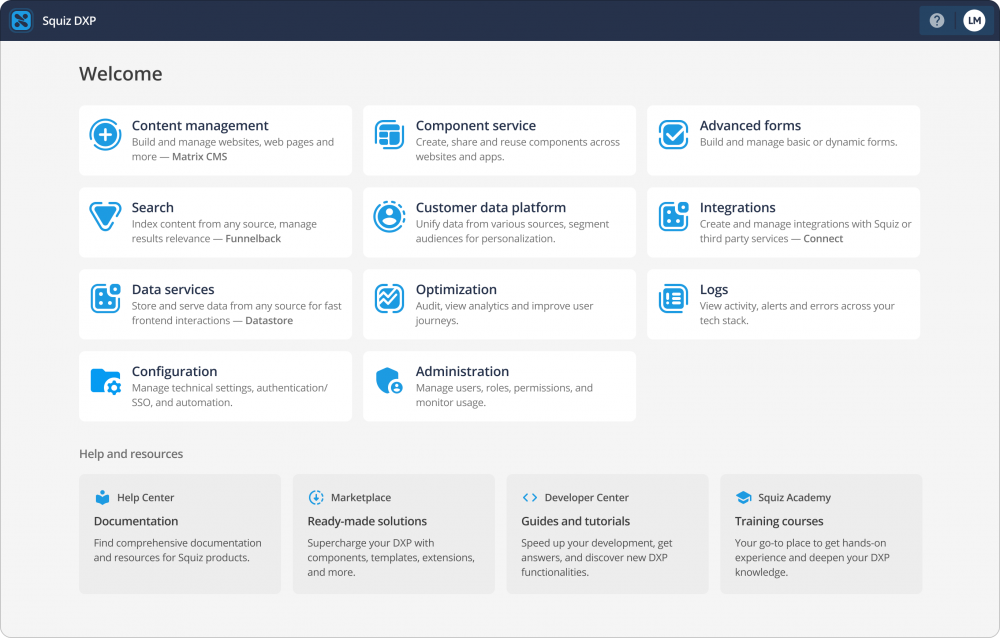





Make siloed content, data and tech work together to deliver one brand experience. Let marketers and developers work in parallel, not backlogs. Govern and secure experiences, even at scale.
Marketers - Create and personalize experiences with low-code tools. Use design systems to stay on-brand, everywhere.
Developers - Spin up sites quickly with pre-built integrations, templates and components. Use industry standard tooling you already know.
Digital teams - Unify customer data and content from any source to deliver multi-channel experiences.
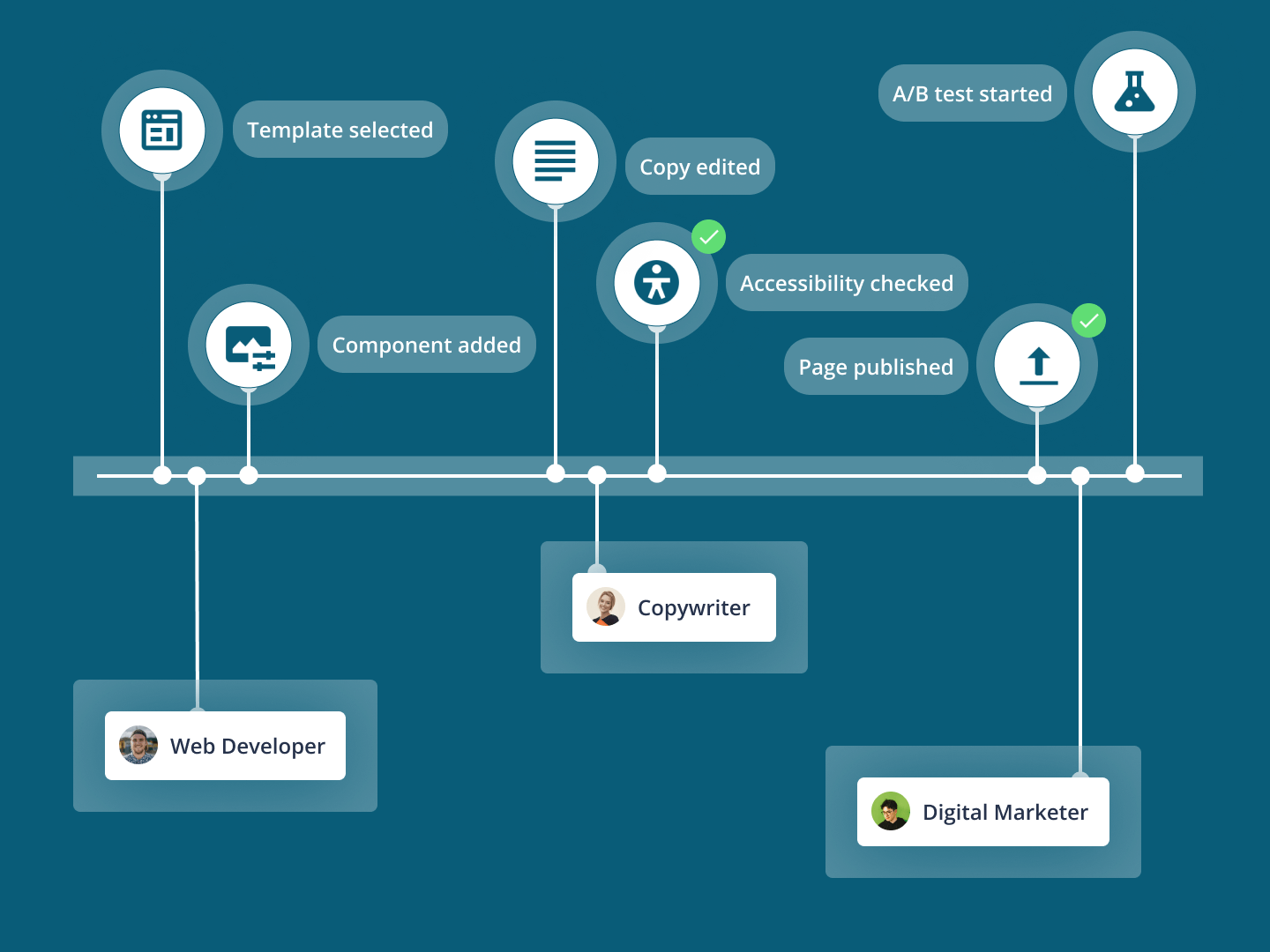
Squiz DXP comes with best-of-class capabilities to create amazing digital experiences.
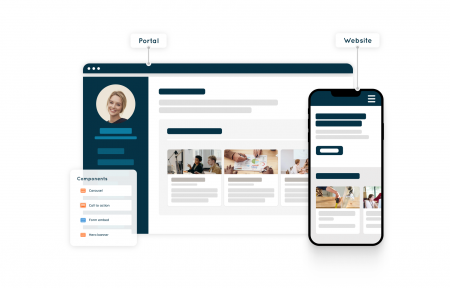
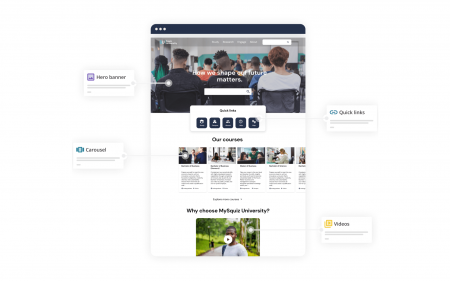
Create compelling experiences on your sites, apps, and portals with a no-code page builder. Easily define how text, images, and layouts come together. Maintain brand consistency at scale.
ViewSpeed up your coding workflow and increase your productivity using our powerful and flexible web component builder.
ViewCreate websites that convert with our low-code content management solution for large, non-technical teams.
ViewEnable your users to find anything with our lightning-fast website search from any source and in any format.
ViewMaximize the impact of your content and drive successful conversions with our suite of analytical tools.
ViewUnify fragmented data and break down silos to provide personalized online experiences.
ViewConsolidate all your tools into a single platform to create more automated processes and personalized content.
ViewMaximize the impact of your experiences by delivering them the way users expect – securely, consistently, and lightning-fast – across web, mobile, IoT devices, digital signage, and more.
ViewUnify and manage your entire tech stack from a secure, centralized platform. Get end-to-end visibility across all your digital experiences with experience monitoring, error logs, and more.
View
Recognized as a global leader in digital transformation, we're invested in your success.
Specializing in serving organizations who serve our communities, Squiz has delivered thousands of digital projects for the worlds most critical service sectors.

We help universities and colleges overcome the education challenges of tomorrow.
Integrate all your existing systems within a single flexible platform and easily orchestrate your content across all your web properties.
Learn more
We work alongside government agencies and local councils to bring services online.
Leverage our flexible and easy-to-use digital platform to deliver efficient public services that meet citizens’ expectations.
Learn more
We help you create secure, frictionless experiences that build customer trust.
Empower users to access personalized records, view transaction history, initiate quotes or queries, and manage their accounts in a secure and user-friendly environment.
Learn more
Create accessible, digital experiences that customers demand. Automate workflows, reduce costs and boost customer satisfaction.
Unlock self-service for digital bill payments, account management and support queries. Shift in-person or phone resources to high-value interactions.
Learn moreDiscover how Squiz helps organizations transform their digital experiences to better serve and delight their audiences.
Facing increasing complexity in maintaining their website and offering more than a content platform, FMG needed to build a new, more flexible solution.
Read moreLarge organizations are moving away in droves from their old CMS to a more robust DXP solution. But should you too?
Read moreSSCL is increasing government employee online self-service to reduce contact center inquiries and costs.
Read moreWhen the biggest property data provider in Australia and New Zealand wanted to overhaul their digital experience, it naturally selected Squiz DXP.
Read moreGovernment organizations are big ships to steer. And when it comes to digital transformation in government, progress can be slow. Enters the DXP.
Read moreGet the best of both worlds across the spectrum of monolithic to composable DXPs with a robust and personalized digital experiences for your users.
Read moreCyber Attacks can pose serious threats to your digital experience platform. Learn how to safeguard your business and leverage Squiz DXP's advanced security features.
Read more